Nachdem ich das Thema Dokumentenarchiv eine ganze Weile hab ruhen lassen, habe ich einen erneuten Anlauf mit Paperless gewagt. Seit meinem letzten Versuch ist die Funktion Speicherpfad hinzugekommen und genau darum sollen es gehen.
Die meisten Programme ordnen die Dokumente intern über eine Datenbank zu. Ist das Programm futsch, dann wars das auch mit den Dokumenten. Paperless ist hier anders. Es besteht die Möglichkeit, anhand von Dokumenteneigenschaften und frei wählbaren Begriffen eine Ordnerstrukur zu bilden, so dass auch ohne Programm die Dokumente leicht auffindbar sind.
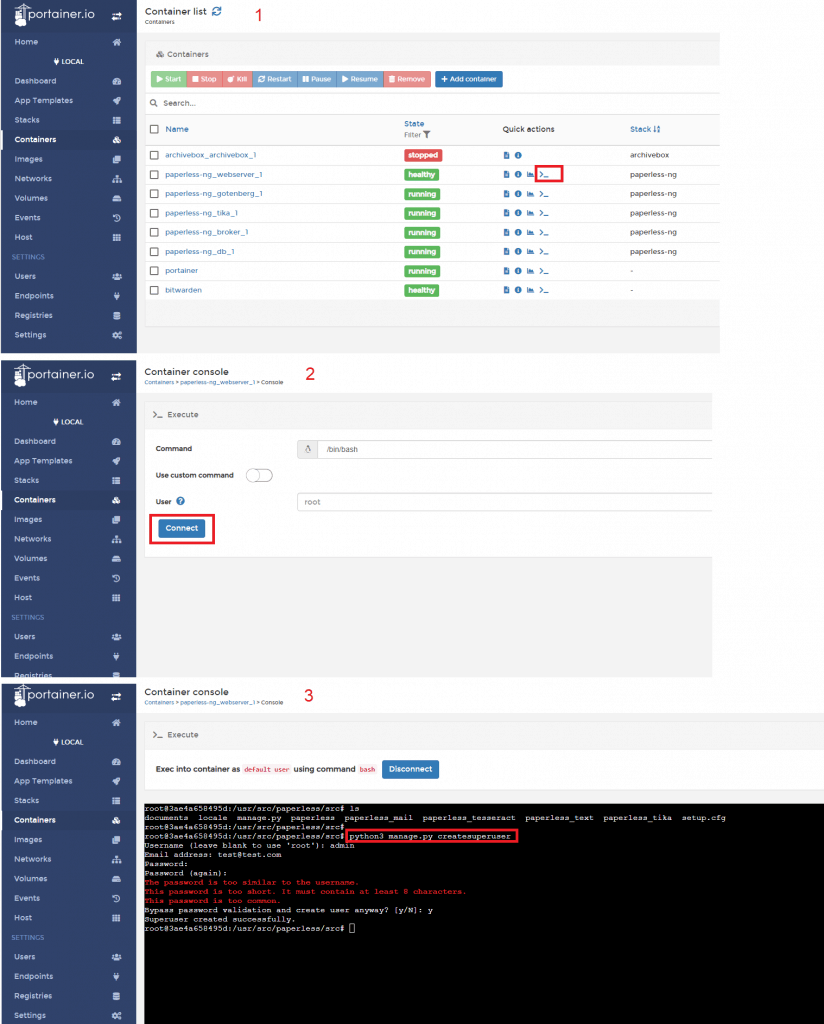
Hier einmal die Eigenschaften des Dokuments - rot markiert die Möglichkeit, einen Speicherort für dieses Dokument zu hinterlegen bzw. eine Voreinstellung auszuwählen (wie in diesem Beispiel geschehen).
Die Voreinstellung der Speicherpfade lassen sie über einen separaten Menüpunkt erstellen.
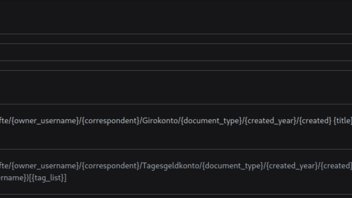
In den geschweiften Klammern lassen sich die Dokumenteneigenschaften abfragen, die Texte ohne Klammern sind frei wählbar, der Schrägstrich steht für eine Ordnerebene.
Bankgeschäfte/{owner_username}/{correspondent}/Girokonto/{document_type}/{created_year}/{created} {title} ({owner_username})[{tag_list}]
Das geniale ist nun, ändere ich einen definierten Speicherpfad, so wird dieser automatisch auf alle Dokumente angewandt, bei denen diese Voreinstellung hinterlegt ist.
Und so sieht es dann auf Ordner- und Dateiebene aus.Für mich ist es so absolut ausreichend, so dass ich Paperless vermutlich als Dokumentenverwaltung einsetzen werde. Natürlich sollte das von Paperless erstellte Archiv regelmäßig auf einem separaten Datenträger gesichert werden.
tree archive/
archive/
└── Bankgeschäfte
├── Alice
│ └── ING
│ └── Girokonto
│ └── Kontoauszug
│ └── 2021
│ └── 2021-03-31 Kontoauszug (Alice)[Girokonto,ING,Kontoauszug].pdf
└── Paul
├── Commerzbank
│ └── Tagesgeldkonto
│ └── Kontoauszug
│ ├── 2021
│ │ └── 2021-09-30 Kontoauszug (Paul)[Commerzbank,Kontoauszug,Tagesgeld].pdf
│ └── 2023
│ ├── 2023-01-31 Kontoauszug (Paul)[Coomerzbank,Kontoauszug,Tagesgeld].pdf
│ └── 2023-05-31 Kontoauszug (Paul)[Commerzbank,Kontoauszug,Tagesgeld].pdf
└── ING
└── Girokonto
└── Kontoauszug
├── 2021
│ ├── 2021-04-30 Kontoauszug (Paul)[Girokonto,ING,Kontoauszug].pdf
│ └── 2021-12-30 Kontoauszug (Paul)[Girokonto,ING,Kontoauszug].pdf
├── 2022
│ ├── 2022-11-30 Kontoauszug (Paul)[Girokonto,ING,Kontoauszug].pdf
│ └── 2022-12-30 Kontoauszug (Paul)[Girokonto,ING,Kontoauszug].pdf
└── 2023
└── 2023-06-30 Kontoauszug (Paul)[Girokonto,ING,Kontoauszug].pdf
Alles anzeigen